LLM强化学习不稳定之谜,被Qwen团队从「一阶近似」视角解开
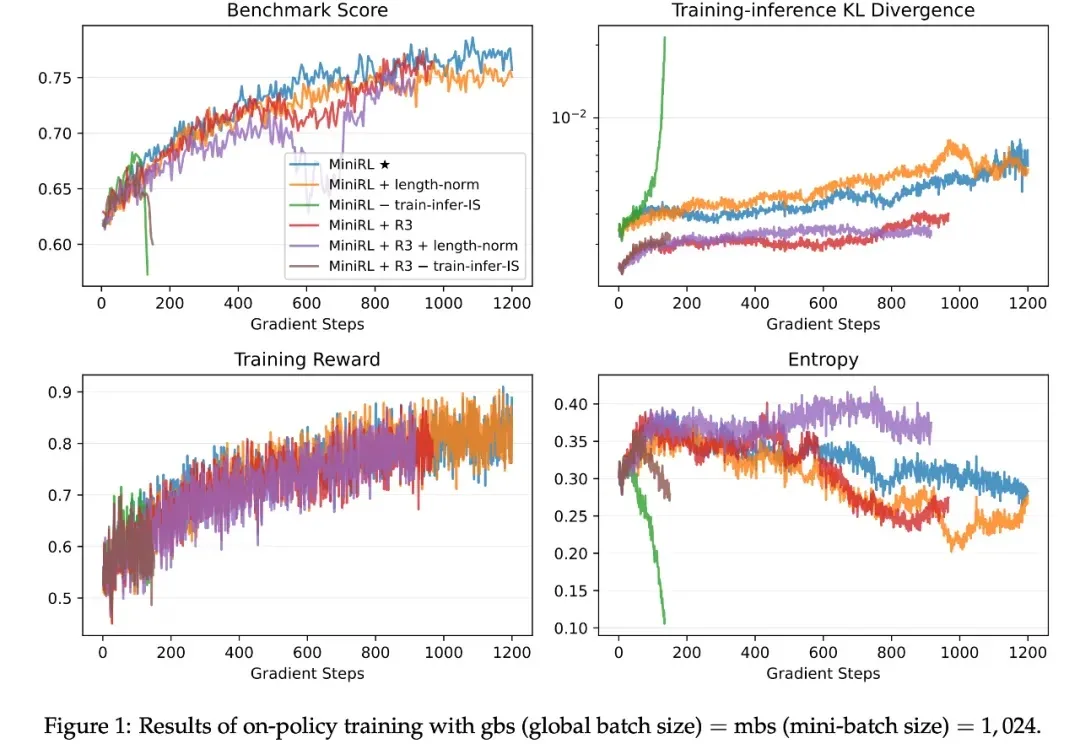
LLM强化学习不稳定之谜,被Qwen团队从「一阶近似」视角解开如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
来自主题: AI技术研报
6424 点击 2025-12-08 10:27
 搜索
搜索
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。
最近两周的模型竞赛非常热闹:OpenAI 在 11 月 12 日发布 GPT-5.1,引入更强的推理深度与更高效的对话体验;Google 在 11 月 18 日发布 Gemini 3,全面强化多模态理解与复杂推理能力;Anthropic 在 11 月 24 日又发布了 Claude Opus 4.5,模型在专业文档处理、代码生成与长流程 agent 方面有显著提升。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
前 OpenAI 联合创始人、特斯拉 AI 总监 Andrej Karpathy 也一样。他在前几天发推,说自己「开始养成用 LLM 阅读一切的习惯」。Karpathy 在周六用氛围编程做了个新的项目,让四个最新的大模型组成一个 LLM 议会,给他做智囊团。
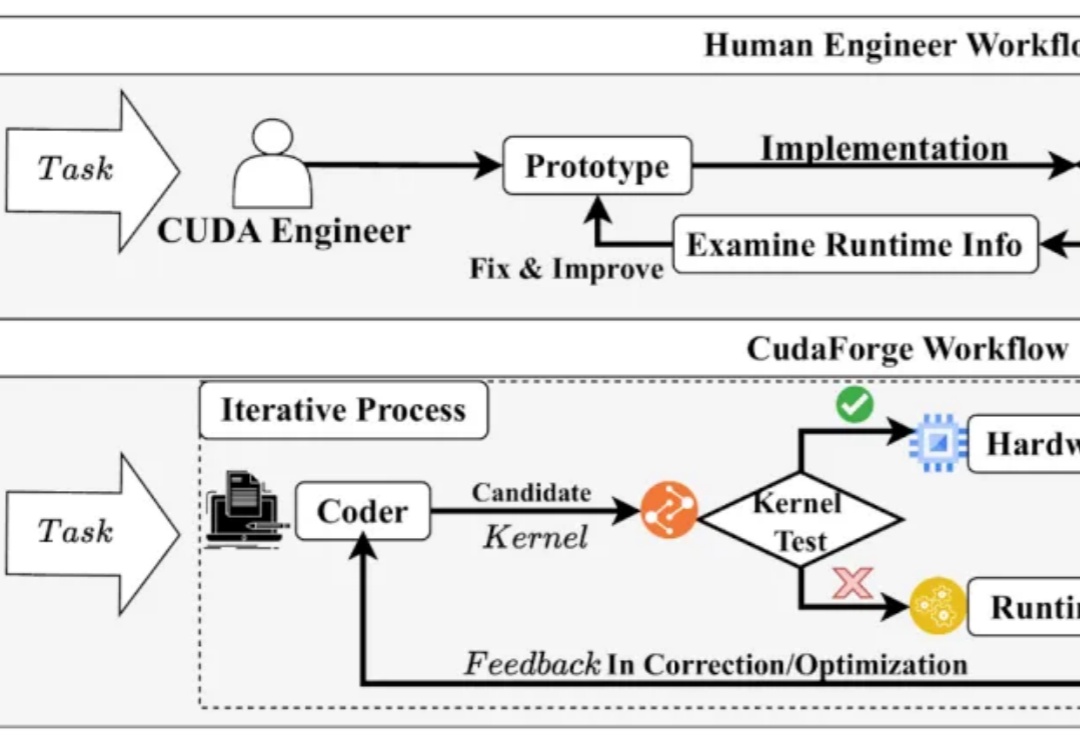
CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。
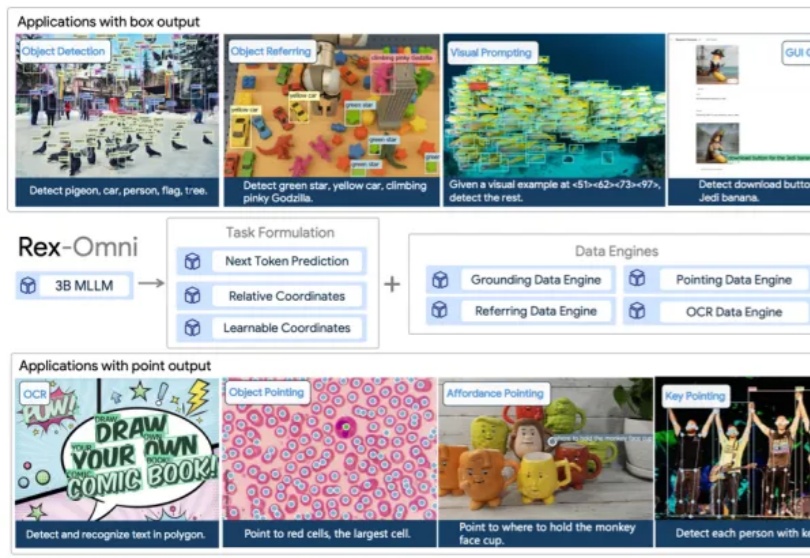
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
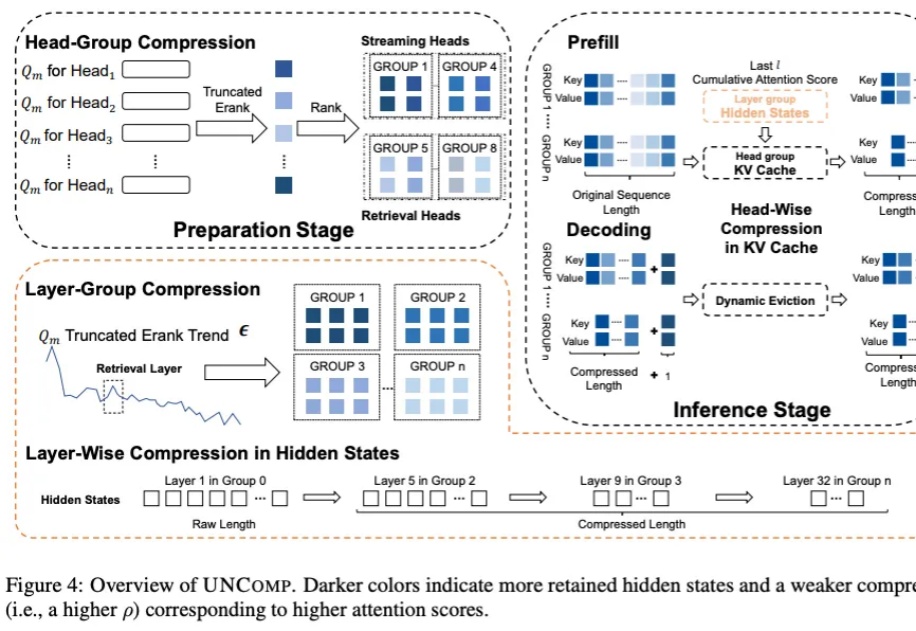
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。